Amazonの社内展開が示した新しい入り口
AIコーディングエージェントをめぐる論点は、開発者が個人で試す段階から、企業がどの基盤なら全社利用を許せるかへ移っている。Business Insiderは2026年5月4日、AmazonがClaude Codeを全社で即時利用可能にし、Codexを2026年5月12日から提供する方針だと報じた。両方ともBedrock上で動き、AWS経由で管理されるという。
これは、Amazon社内の開発支援ツールKiroが消えるという単純な話ではない。より大きい変化は、外部のコーディングエージェントが、企業の承認済み選択肢として社内標準の棚に並び始めたことだ。
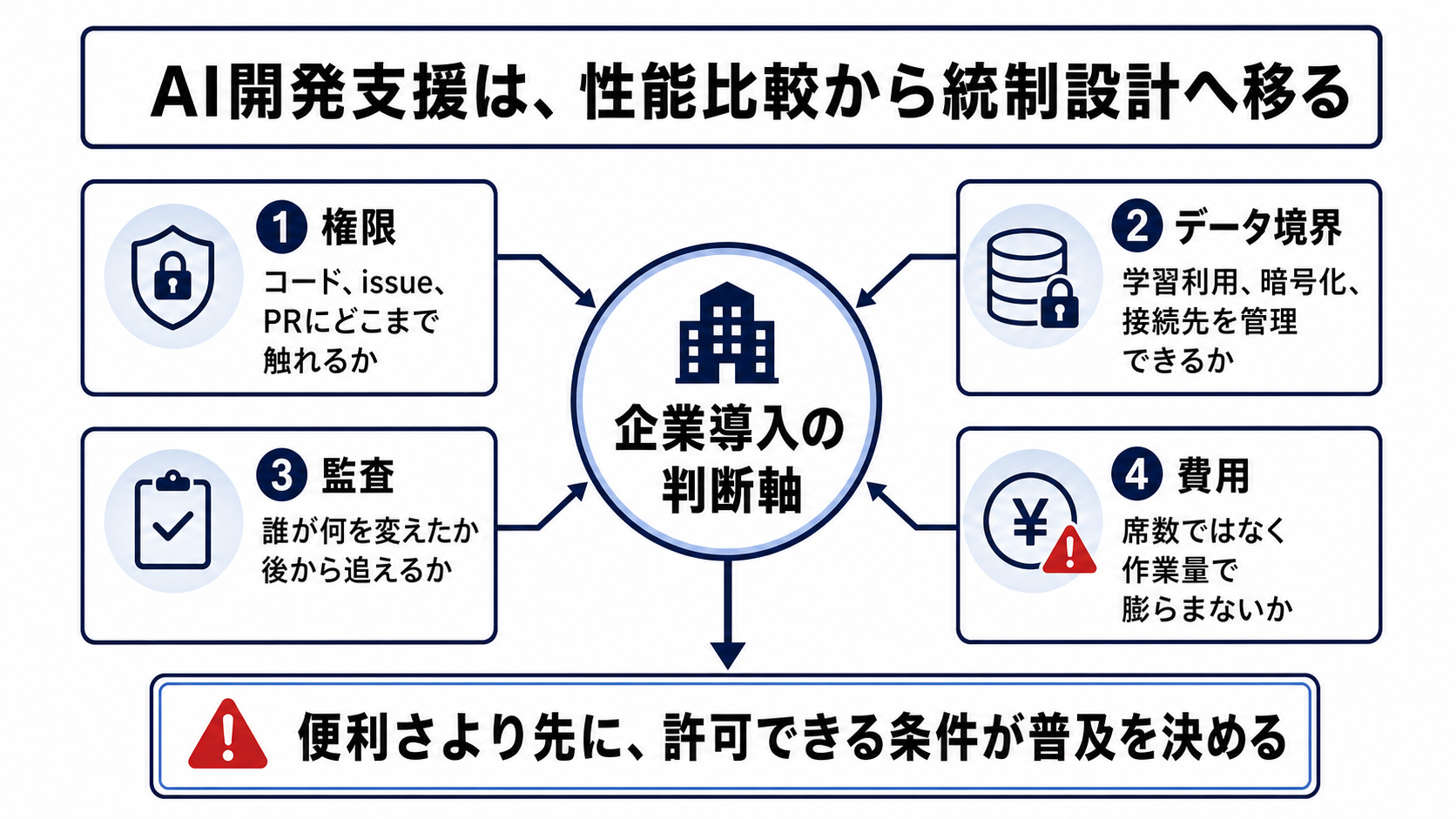
導入の入口が変わると、比較対象も変わる。モデル単体の賢さだけでなく、AWSの管理、社内の権限設計、利用ログ、費用管理、既存契約との整合性が、採用可否を決める材料になる。
コーディングAIはモデル単体の勝負ではなくなった
AWSは2026年4月28日、Amazon BedrockでOpenAIモデル、Codex、OpenAI powered Managed Agentsを限定プレビューとして提供すると発表した。Bedrock上のOpenAIモデルはIAM、PrivateLink、guardrails、暗号化、CloudTrail loggingなどの統制を継承する。企業にとっては、モデルを使えることより、既存の統制面に乗ることが意味を持つ。
GitHubも同じ方向を向いている。2026年2月26日の発表では、Claude、Codex、CopilotをGitHub内の単一プラットフォームで使えるようにし、EnterpriseとBusinessでは中央の有効化、ポリシー管理、監査ログをAgent Control Planeで扱うと説明した。開発者が使う画面と、管理者が許可する面が近づいている。
GoogleのGemini Code Assist Standard/Enterprise文書も、プロンプトと応答を同モデルの学習に使わないこと、転送中の暗号化、生成コードの安全性や検証責任が利用側に残ることを明記している。各社が前面に出しているのは、純粋な性能比較ではなく、企業が許可しやすい条件だ。
この構造は、モデル選択の自由度とベンダー基盤への固定化を同時に進める。企業は複数モデルを選べるようになる一方で、実際の導入はAWS、GitHub、Google Cloud、既存のリポジトリ管理、ID管理、監査基盤に強く縛られる。
公式統制と社内展開を分けて読む
今回の材料は、公式に確認できる統制機能と、Amazon社内の展開報道を分けて読む必要がある。公式発表で確認できるのは、AWS BedrockがIAMやPrivateLink、guardrails、暗号化、CloudTrail loggingなどを統制面として示していること、GitHubがAgent Control Planeで有効化、ポリシー管理、監査ログを扱うこと、Googleが学習不使用や暗号化を企業向けの条件として説明していることだ。
一方で、Amazon社内でClaude Codeが即時利用可能になり、Codexが2026年5月12日から提供されるという部分は報道ベースの事実である。ここから直ちに投資対効果や全社の利用実績を読むのは早い。読めるのは、Amazonのような大企業でも、外部エージェントをAWSの管理面に載せて承認済みの選択肢にする動きが出ているということだ。
この切り分けが重要なのは、AI開発支援のニュースが機能紹介に流れやすいからだ。導入判断で効くのは、デモの迫力ではなく、企業が法務、セキュリティ、調達、開発部門を同時に説得できる条件がそろっているかである。
権限を渡すほど生産性と監査が同時に重くなる
コーディングエージェントは、質問に答えるチャットボットとは違う。実用化が進むほど、リポジトリのコード、履歴、issue、PR、設定、社内の開発ルールを文脈として扱う。便利になるほど、触れてよい範囲を細かく決める必要が出る。
開発者にとっては、issueの理解、修正案の作成、テスト、draft PRの準備まで進めてくれるほど価値が高い。だが管理者やセキュリティ部門から見ると、その価値はアクセス権の拡大と同義になる。どの組織で有効にするか、どのモデルを許すか、どのリポジトリに接続できるか、どのログを残すかが、導入の中心になる。
そのため、成果物はレビュー可能な形で残る必要がある。draft PR、差分、テスト結果、監査ログのように、人間が後から責任を持てる形式に落ちるなら、企業は権限を広げやすい。反対に、何を根拠にどのコードを変えたのかが追えないエージェントは、性能が高くても全社利用には乗りにくい。
知財とデータ境界が使える範囲を決める
企業導入を止める理由は、性能不足だけではない。むしろ稟議で重くなるのは、社内コードや設計情報がどこへ送られるのか、プロンプトや応答が学習に使われるのか、生成コードにライセンスや安全性の問題が混ざった時に誰が責任を持つのかである。
GoogleのGemini Code Assist Standard/Enterprise文書は、プロンプトと応答を同モデルの学習に使わないこと、転送中に暗号化されることを示す一方で、生成コードの安全性や検証責任は利用側に残ると整理している。企業向けの補償や認証は安心材料になるが、完成物をそのまま本番へ入れてよいという意味ではない。
ここで差が出るのは、法務と情報管理が判断できる粒度だ。データ境界、学習不使用、監査、補償、ライセンス確認の役割が明確なツールは承認されやすい。境界が曖昧なツールは、開発者の評価が高くても、機密度の高いコードや顧客情報に近い開発では制限されやすい。
料金は席数から作業量へ寄っていく
AI開発支援の費用も、単純な月額席数だけでは読みにくくなる。GitHubはCopilotについて、2026年6月1日からAI Creditsによる利用量課金へ移す。組織・企業向けでは、入力、出力、キャッシュされたトークン消費が課金単位になり、BusinessとEnterpriseでは共有プールとして扱われる。
これは、自律エージェントの使い方に直接効く。短い補完や質問なら費用は予測しやすいが、長時間にわたってコードを読み、修正し、テストし、PRを準備する使い方では、作業量そのものが費用変数になる。生産性が上がっても、予算上限や部門別の利用配分を設計できなければ、全社利用は止まりやすい。
Bedrock経由で使う場合は、既存AWS契約との関係も導入判断に入る。すでにAWSでID、ネットワーク、監査、請求をまとめている企業にとっては、同じ管理面でAIエージェントを扱えることが購買上の利点になる。反対に、クラウド契約や開発基盤が分散している企業では、費用の見える化と権限の整理が先に必要になる。
広がる企業と止まる企業を分ける条件
導入が広がる条件は、承認までの時間が短くなり、利用範囲が明確になり、管理ログと費用が見えることだ。Amazonのような全社展開が他社にも広がり、用途別の制限や承認フローが整えば、AIコーディングエージェントは一部の先進開発者向けツールから、標準の開発基盤へ近づく。
反対に、費用超過、生成コードの品質問題、ライセンス懸念、監査不備、セキュリティ事故が表面化すれば、企業は利用範囲を絞る。モデル固定、リポジトリ単位の許可、出力レビューの義務化、管理者承認の強化が進む可能性が高い。
企業が今比較すべきなのは、モデル名の序列ではない。誰が権限を与え、どのデータ境界で動き、どのログが残り、どの費用単位で膨らみ、生成物を誰が検証するのかだ。そこが見える企業から導入は進み、見えない企業では、便利さが確認されても全社利用の手前で止まる。